How to Set Up LocalAI with Docker

LocalAI with Docker runs an OpenAI-compatible inference server on your own hardware, with no API costs, no data leaving the machine, and no cloud dependency. This guide covers one job:
Know your tech
LocalAI with Docker runs an OpenAI-compatible inference server on your own hardware, with no API costs, no data leaving the machine, and no cloud dependency. This guide covers one job:

Running your first local AI model with Ollama takes one pull command and one terminal prompt, no cloud account, no API key, no Python environment to configure. Ollama manages everything
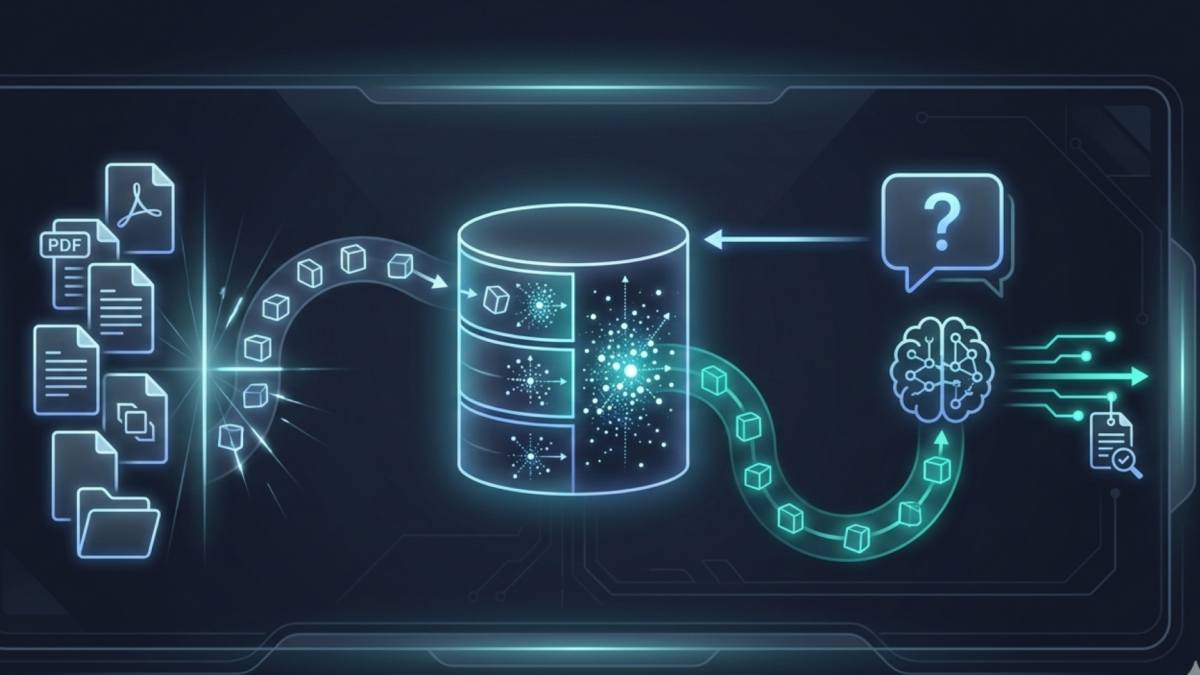
RAG Retrieval-Augmented Generation is the technique that lets AI models answer questions from your documents rather than from their training memory. It fixes the single biggest limitation of local AI:
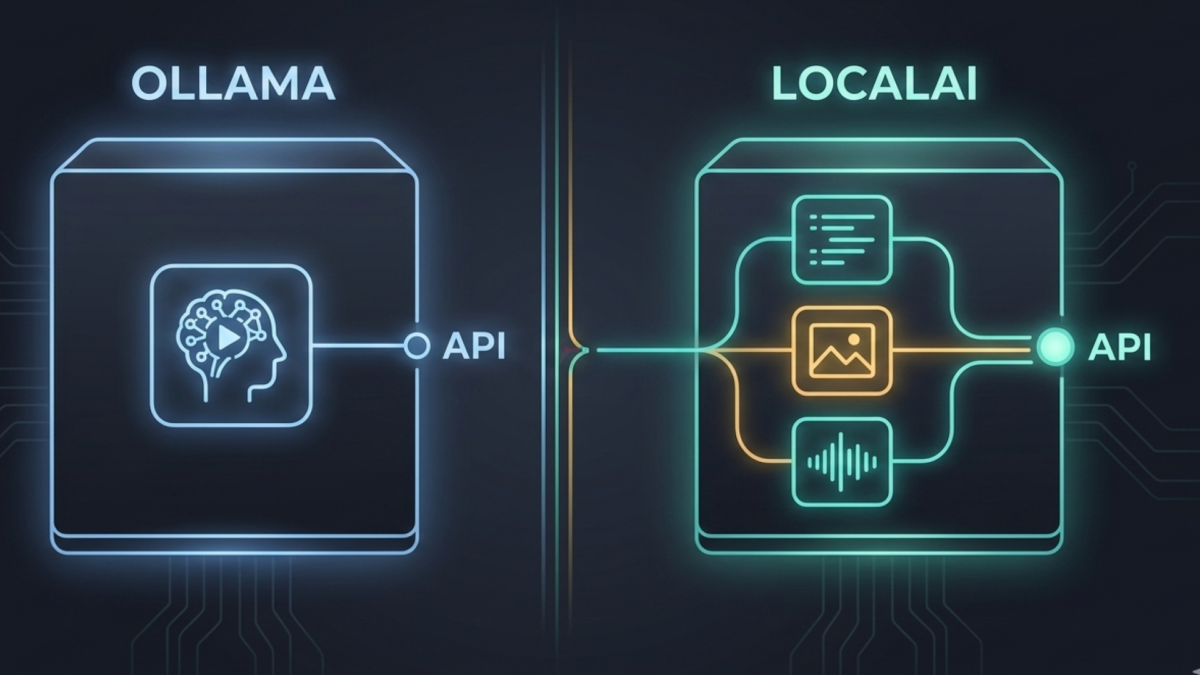
Ollama and LocalAI both run AI models locally on your own hardware. But they are built for different problems, different users, and different stages of a homelab’s growth. Understanding the