RAG Retrieval-Augmented Generation is the technique that lets AI models answer questions from your documents rather than from their training memory. It fixes the single biggest limitation of local AI: the model only knows what it was trained on. RAG opens the book.
What RAG Actually Is
RAG stands for Retrieval-Augmented Generation. The name describes the process precisely. Before generating an answer, the system retrieves relevant information from your documents and augments the prompt with that information. The model then generates its response using the retrieved content as its primary source rather than its training memory.
The result is an AI that answers questions about your specific documents accurately, not because it was trained on them, but because it looked them up first. It is the difference between a student answering from memory and a student reading the relevant passage before writing. The model’s underlying capability is the same. What changes is the information it is working from.
Why You Cannot Just Paste Documents Into the Chat
The obvious question is why RAG is necessary at all. Modern language models have large context windows; some can accept hundreds of pages of text in a single prompt. Why not simply paste the documents and ask questions?
Pasting documents into every query is expensive, slow, and surprisingly ineffective. Processing a large document with every single question means the model re-reads the entire thing each time, which is computationally costly and slow. More importantly, when you give a model five hundred pages of text and ask a specific question, the relevant paragraph gets lost in the noise. The model struggles to find the needle in the haystack you just handed it.
The deeper problem is that pasting documents does not solve the training cutoff issue. The model still does not know your documents in any persistent sense; it is reading them fresh each time, expensively, with no memory of previous queries. RAG builds a searchable index of your documents and pulls only what is relevant at the moment you ask. It is architecturally smarter in every dimension.
How RAG Works: The Two Phases
RAG operates in two distinct phases that happen at different times and serve different purposes.
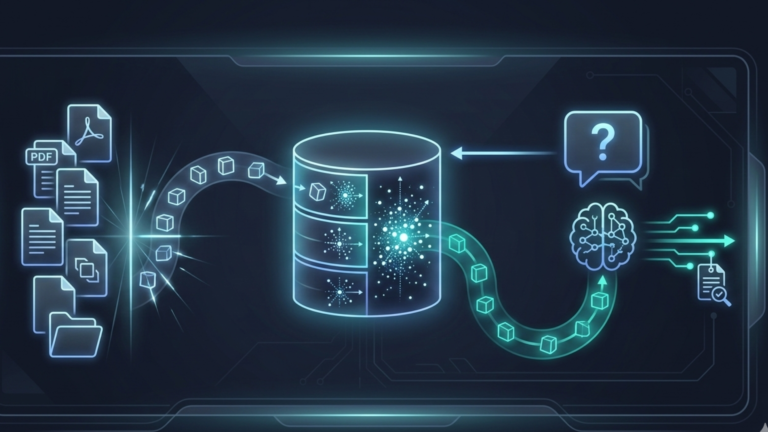
The first phase is indexing, and it happens once as preparation. Your documents, PDFs, Word files, text files, whatever you are working with, are loaded into the system and split into chunks, typically a few hundred to a thousand characters each. Each chunk is then passed through an embedding model, which converts the text into a vector, a list of numbers that mathematically represents the meaning of that chunk. These vectors are stored in a vector database optimized for fast similarity search. After indexing, your documents exist as a searchable map of meaning.
The second phase is generation, and it happens every time someone asks a question. The question itself is converted into a vector using the same embedding model. The vector database compares the question’s vector against all the document chunk vectors and finds the chunks with the closest semantic meaning, not keyword matches, but meaning matches. Ask “how do I get my money back,” and it finds the chunk about the refund policy even if the word “money” never appears in that policy. The most relevant chunks are retrieved, combined with the original question into an enhanced prompt, and sent to the language model, which generates its answer using that retrieved content as its source.
This is why RAG works where context-window stuffing does not. Instead of making the model search through everything, you do the searching first and hand it only what matters.
The Embedding Model: The Hidden Key
The piece of RAG that most explanations underemphasize is the embedding model, because it is doing the most important work in the system.
An embedding model converts text into vectors in a way that preserves semantic relationships. Similar meanings produce similar vectors. This is what makes semantic search possible: the system finds chunks that mean the same thing as your question, even when the words are different. The quality of your RAG system depends heavily on the quality of its embeddings, because poor embeddings produce poor retrieval, and poor retrieval means the language model is generating answers from the wrong source material, regardless of how capable it is.
For local homelab deployments, lightweight embedding models like all-MiniLM run entirely on your hardware and perform remarkably well for most use cases. The entire RAG pipeline document processing, embedding, vector storage, retrieval, and generation can run locally with no data leaving your network.
RAG vs Fine-Tuning
The other approach to giving a model knowledge of your documents is fine-tuning, actually training the model on your data so that knowledge becomes part of its weights. RAG and fine-tuning are frequently confused, but they solve different problems.
Fine-tuning embeds knowledge permanently into the model. It is appropriate when you need the model to adopt a specific style, follow particular output formats, or learn tasks that do not depend on specific documents. The trade-off is that it is expensive, time-consuming, and inflexible when your documents change, you retrain.
RAG leaves the model unchanged and retrieves knowledge at query time. It is appropriate when your documents change frequently, when you need citations so answers can be verified, or when privacy requires that sensitive documents never leave your infrastructure. When your documents update, you re-index. No retraining required.
Most production systems eventually use both fine-tuning for behavior and style, RAG for factual, document-grounded content. But for home lab use cases involving private documents, RAG alone handles almost everything you need.
Why It Belongs in a Homelab
Ollama runs your local language models. Open WebUI makes them accessible. RAG is the layer that connects those tools to your actual knowledge, your documentation, your notes, your research, and your records.
Without RAG, a local AI setup is a capable general-purpose tool. With RAG, it becomes a system that understands your specific context. You can query your homelab documentation and get answers grounded in your actual configuration. You can ask questions about documents containing sensitive information and know that nothing left your network. You can build a knowledge base from files that have been accumulating for years and make that knowledge searchable through natural conversation for the first time.
Open WebUI has RAG built in. You upload documents, it handles the indexing, and your local models gain the ability to answer questions grounded in those documents entirely on your own hardware. The ingredient is already in your stack. Understanding what it does and why it works is what lets you use it deliberately.
The Takeaway
RAG prevents hallucination by replacing memory with evidence. It indexes your documents as searchable vectors, retrieves the most relevant chunks when a question is asked, and grounds the model’s response in that retrieved content rather than in guessing. It works with private documents without requiring retraining. It runs entirely locally with no data leaving your network. Every useful thing you can build with local AI and your own documents builds on this.









