Model quantization is the process of reducing the precision of the numbers inside an AI model, so it takes up less memory and runs faster without meaningfully changing what it can do. It is the primary reason large AI models can run on hardware you actually own.
The Problem: AI Models Are Enormous
Modern AI models like Llama 3 or Mistral contain billions of numbers called weights. These weights define everything the model knows and how it thinks. By default, each weight is stored as a 32-bit floating point number, a very precise decimal, like 3.1415926535897932.
A 7-billion-parameter model stored this way needs roughly 28GB of memory just to load. That rules out most laptops and every smartphone.
What Quantization Does
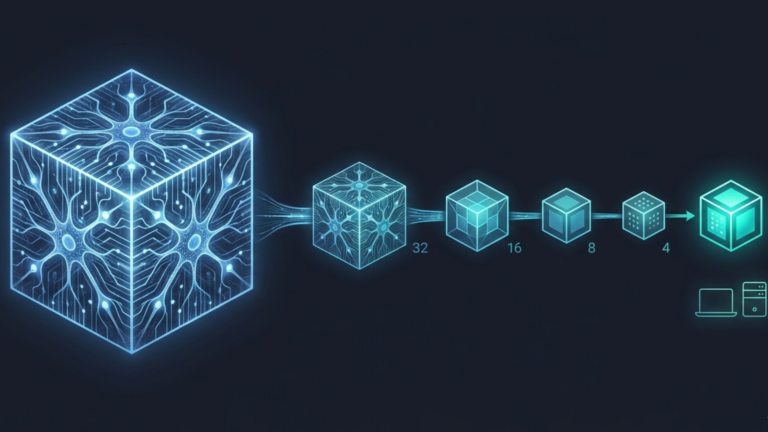
Quantization reduces how precisely those numbers are stored. Instead of keeping 3.1415926535897932, you round it to something like 3.14 or even just 3.
Think of it like this: you have a 50-volume encyclopedia where every number is written to 16 decimal places. It is precise but enormous. To make it portable, you create a pocket version where every number is rounded to the nearest whole number. You lose a tiny amount of detail, but the knowledge is still there, and now it fits in your bag. That is exactly what quantization does to an AI model.
The Precision Spectrum
Different levels of quantization exist, each with a different trade-off between size and accuracy.
FP32 (32-bit) is full precision how most models are trained. Large, slow, and accurate. FP16 and BF16 (16-bit) are half precision, noticeably smaller and faster with almost no accuracy loss, and widely used in practice. INT8 (8-bit) is the most common deployment format, making a model 4x smaller than FP32 with accuracy differences that are undetectable for most tasks. INT4 (4-bit) is an aggressive compression; it allows very large models to run on consumer hardware or phones with some accuracy loss, though improving rapidly with better techniques.
When you see a model named Llama-3-8B-Q5_K_M, the Q5 tells you it is 5-bit quantized. That naming convention appears across tools like Ollama and LM Studio and is worth recognizing immediately.
Why It Matters
Quantization closes the gap at two scales. At the personal level, tools like Ollama and LM Studio use quantized versions of models like Llama 3, making them small enough to run on a laptop or home server without a data center GPU. At the mass market level, the offline mode in Google Translate and real-time effects in apps like Instagram already rely on heavily quantized models, which means this is not experimental technology. It is proven, running quietly on billions of devices right now.
The Takeaway
Quantization trades a small amount of numerical precision for a large gain in usability. A 7-billion-parameter model that would need 28GB at full precision can run comfortably in 4 to 6GB when quantized on hardware sitting on your desk right now. For most real-world tasks, an INT8 model performs indistinguishably from its full-precision counterpart. It is what bridges the gap between models trained on data center hardware and inference running on your own.









